Dockerコンテナで起動したGUIをlocalで表示する方法
xhostコマンドを使うことで可能になります。xhostコマンドは、Xサーバへのアクセスの許可/不許可を設定するためのコマンドです。設定をするためには、Xサーバのクライアント・サーバそれぞれで設定が必要になります。
サーバ側
xhost +hoge.co.jp
のように記述すれば、hoge.co.jpからのアクセスを許可します。
xhost +
のように、+の後に何も書かないと、全てのアクセスを許可することになります。そのため、第三者がアクセスしてきても、そのアクセスを許可してしまっている状態なので注意が必要です。xauthなどの別のコマンドを使うことで、それを回避できます。
逆に追加したアクセスを削除するには、
xhost -hoge.co.jp
のように、+の代わりに-をつければOKです。
現時点で誰にアクセス許可をしているかを調べるには、
xhost
とだけ打てば表示されます。
クライアント側
環境変数DISPLAY にXサーバーのホスト名、もしくはIPアドレスを指定する必要があります。指定時の書式は、
# DISPLAY=Xサーバー名:ディスプレイ番号.スクリーン番号
です。デフォルトでは何も指定されていないので、hoge.co.jpを追加してみます。
$ printenv DISPLAY :0.0 $ export $DISPLAY=hoge.co.jp:0.0 $ printenv DISPLAY hoge.co.jp:0.0
のようになるはずです。上記を.bashrcなどに追加しておけば、次回以降も自動的にXサーバへのアクセス設定が追加された状態になります。
Linux上のプロセスは、UNIXドメインソケットを使って通信を行っています。Xサーバも、
/tmp/.X11-unix/
にあるソケットファイルを使用して通信を行っている。そのため、Dockerコンテナがこのソケットファイルを使用することで、local上にGUIを表示することが可能となる。そのため、コンテナを生成する時に-vオプションを使い、上記localのソケットファイル格納場所をDockerコンテナ上の同じ場所にマウントしてあげる必要がある。
Dockerが動いてるのはlocal上であり、特に指定しない限りrootユーザでコンテナが生成されます。そのため、
xhost +local:root
とすると、Dockerコンテナを登録できます。特に表示先のディスプレイにこだわりがなければ、コンテナ生成時に環境変数を指定するオプション
-e DISPLAY=$DISPLAY
を付ければOKです。
Ubuntu / Windowsの両方で使える外付けHDDの暗号化方法
結論として、VeraCryptを使うのがよい。というか、私が試した限りこれしかダメだった。
Ubuntu上で暗号化をしようとすると、[1]では、cryptsetupというパッケージが必要だとしている。このパッケージがUbuntuではデファクトなようだ。しかしこれを使って暗号化できるのは、ext4のパーティションだけである。ext4は、通常ではWindows上で開くことができない。
そこで調べてみると、Ext2Fsd[3]というソフトをインストールすることで、Windows上でもext4のファイルシステムを読み書きできるようになることを期待したが、結果ダメだった。
そこでVeraCryptを試すと、Win/Ubuntuの両方でドライブおよびファイルをread&writeできた。なお私が暗号化したのはWin10上で、ファイルシステムはNTFSとした。Ubuntuは18.04を使った。
注意点としては、ドライブをマウントする時に、Win/UbuntuのどちらもVeraCryptを介して行う必要がある。
[1]Ubuntu – How to encrypt external devices – iTecTec
[2]Ubuntuで外付けストレージを安全に使用するためにVeraCryptを使う
[3]Linux ext4パーティションをWindows 10にマウントする方法 - Qiita
NVIDIA公式のdockerを使うための環境構築
NVIDIAの佐々木さんの記事を見ると、Docker 19.03以降では、nvidia-docker2をインストールすればよいようです。Docker 19.03よりも前のバージョンの方、および昔のバージョンと互換性をもたせたい場合は、NVIDIA Toolkitのインストールが必要だそうです。
medium.com
公式ページを辿っていけば、問題なくインストール可能だと思います。
docs.nvidia.com
一方で、私はUbuntu 20.04を使っているのですが、
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) && curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - && curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
OK
deb https://nvidia.github.io/libnvidia-container/stable/ubuntu18.04/$(ARCH) /
#deb https://nvidia.github.io/libnvidia-container/experimental/ubuntu18.04/$(ARCH) /
deb https://nvidia.github.io/nvidia-container-runtime/stable/ubuntu18.04/$(ARCH) /
#deb https://nvidia.github.io/nvidia-container-runtime/experimental/ubuntu18.04/$(ARCH) /
deb https://nvidia.github.io/nvidia-docker/ubuntu18.04/$(ARCH) /
<||
となり、sources.list内に記載されるURLにはubuntu18.04でした。
>||
$ . /etc/os-release;echo $ID$VERSION_ID
ubuntu20.04
||
と出るので、公式の通り(NVIDIAが想定するように)処理した結果であり、問題ないとは思います。実際に、
>||
$ sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi
Sun Dec 20 06:44:13 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.27.04 Driver Version: 460.27.04 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce MX330 On | 00000000:2D:00.0 Off | N/A |
| N/A 50C P0 N/A / N/A | 277MiB / 2002MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
||
複数バージョンのCUDAを1つのマシンにインストールする
下記の2つの記事を見る限り、CUDAはバージョン毎に異なるディレクトリに自動的にインストールされるので、異なるバージョン間でファイル自体が競合することはないようです。その一方で、インストール時にCUDAというシンボリックリンクが生成されるので、シンボリックを削除する、update-alternativeのようなもので指す場所を手動で変更する、などの対処が必要になります。個人的には、前者にしておけば、要らぬ混乱が起きないので便利と思います。
medium.com
notesbyair.github.io
なお、最新版のCUDAのインストール方法は、NVIDIAの佐々木さんが書かれている記事を参考にされるのが良いと思います。
■
TransformerはGoogleが[3]で発表したRNNの一種で、Encoder-Decoderをベースにしています。Encoder-Decoderは、テキスト翻訳のために考えられたモデルであり、入力(翻訳元、ソースと呼ばれる)テキストと出力(翻訳先、ターゲットと呼ばれる)テキストのペアを学習データとして使用します。データは下記のようにシーケンス上に処理されます。そのため、Encoder-DecoderモデルはSequence-to-sequenceとも呼ばれます。なおEncoderはA - Cが入力されているブロック群、Decoderは
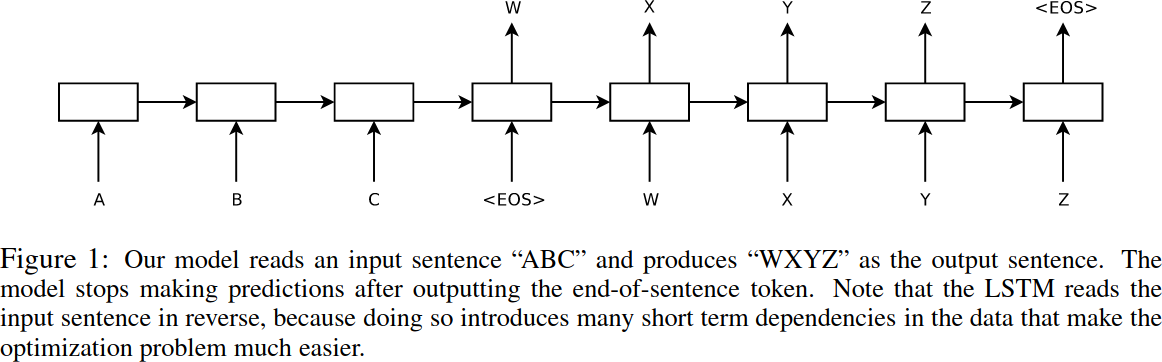
Encoder-Decoderモデルは、翻訳元テキストをEncoderで1つの文脈ベクトルとして纏めてDecoderに入力しており、単語の語順は考慮していません。これは、時系列情報(単語の語順)を無視していることにほかなりません。そこでAttentionという手法が提案され、単語の語順を考慮するようになりました。
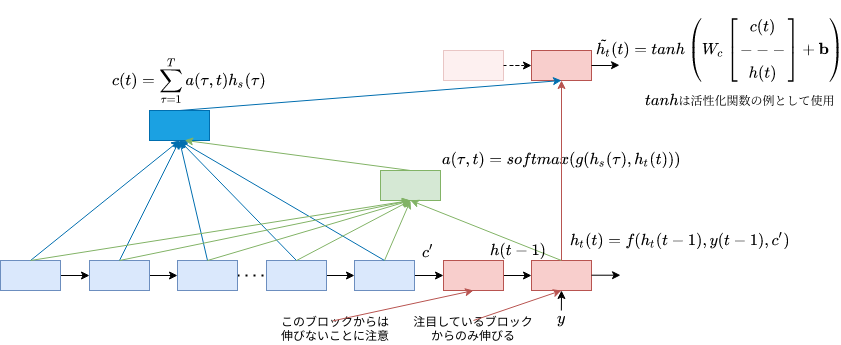
またEncoder-Decoderモデルは、再帰計算が必要なLSTMやGRUを使って長期記憶を実現しているため、並列計算ができず学習速度が遅いという欠点があります。そこで[3]では、Positional Encodingを利用することで、時系列データに直接順序・位置関係の情報を埋め込み、再帰計算を無くしています。
Attentionは、元々翻訳元(ソース)と翻訳先(ターゲット)を組み合わせて計算を行っていました[1][2]。これをSource-Target Attentionと言います(Source-Target Attentionと言い出したのは、[3]からのようですが)。これに加え、TransformerではSource-Source、Target-Targetの組み合わせのAttentionも使われていて、Self-Attentionと総称されています。Self Attentionは、Source-Target AttentionがTargetの隠れ層にSourceの時系列情報の考慮を目的としていることを踏まえると、自身の時系列情報を考慮して隠れ層を学習していくことが目的と考えられます。TransformerではLSTMなどの長期記憶を用いていないので、そういう観点でもSelf Attentionを利用する意図が理解できます。
Positional Encodingは、テキストから生成されたID行列に対し、各単語の位置情報(Aという単語はi番目で、Bという単語は・・・、のような情報)を組み込むことを目的に導入されました。[5]が解説としてわかりやすいかと思います。Positional Encodingは、各単語に対して下記のpを追加します。下記の式のtは単語の位置、kはk < Position Encoding出力の次元数/2、を満たす正数を表します。
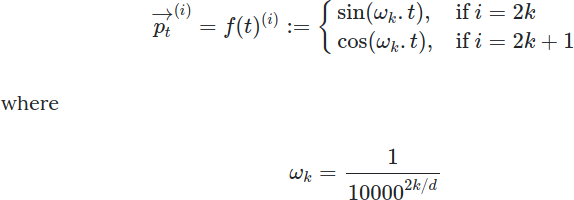
最終的に求まるpは、
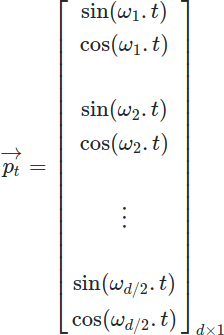
となります。[5]では、これは位置をビットで表現するようなもので、浮動小数点でビット表現するのはイマイチなのでsin/cosを使っているとと言っています。

参考文献
1. "NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE"
2. "Effective approaches to attention-based neural machine translation"
3. "Attention is all you need"
4. 巣籠悠輔, "詳細ディープラーニング 第二版", 2019
5. Amirhossein Kazemnejad, "Transformer Architecture: The Positional Encoding", 2019
6. Ilya Sutskever, et al., "Sequence to Sequence Learning with Neural Networks", arXiv, 2014.
imagemagickを使ったgifアニメーション作成
処理画像を作成した後、それをアニメーション化したい時があるかと思います。その時に、私はimagemagickを使ってアニメーションを作成します。その際ファイルサイズの関係から、解像度を落としたり、最適化して圧縮したりなどすることがあります。今回はそれらを調べた結果についてまとめたいと思います。
GIFアニメーションの作り方
convertコマンドを使います。使いかたは下記の通りです[1]。
convert -delay 5 -loop 0 frame_*.png movie.gif
delayの後の数字は、フレーム間の遅延(時間間隔)を、loopの後の数値はループ再生のあり(1を指定)/なし(0を指定、例はこのパターン)を表します。ファイル名のしては、ワイルドカードが使えます。
GIFアニメーションのリサイズ
同じくconvertを使います。使用するオプションは、%で表現したい場合はscale、解像度で直接指定する場合はresizeを使います。具体的には、
convert source.gif -coalesce -scale 50% -deconstruct output.gif
や
convert source.gif -coalesce -resize 250x250 -deconstruct output.gif
を使います[2]。
・GIFアニメーションの最適化
convertとoptimizeオプションを使います[3]。最適化の中身については、[4]が詳しいと思います。
convert in.gif -coalesce -resize 幅x高さ -layers optimize out.gif
ただ個人的には、optimizeしてもファイルサイズは大して減らない印象があります。最適化よりもリサイズの方が圧倒的にオススメです。