TransformerはGoogleが[3]で発表したRNNの一種で、Encoder-Decoderをベースにしています。Encoder-Decoderは、テキスト翻訳のために考えられたモデルであり、入力(翻訳元、ソースと呼ばれる)テキストと出力(翻訳先、ターゲットと呼ばれる)テキストのペアを学習データとして使用します。データは下記のようにシーケンス上に処理されます。そのため、Encoder-DecoderモデルはSequence-to-sequenceとも呼ばれます。なおEncoderはA - Cが入力されているブロック群、Decoderは
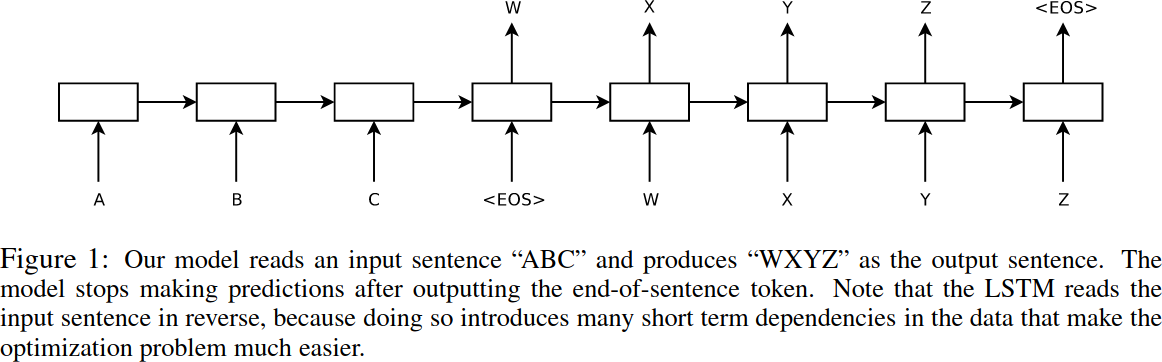
Encoder-Decoderモデルは、翻訳元テキストをEncoderで1つの文脈ベクトルとして纏めてDecoderに入力しており、単語の語順は考慮していません。これは、時系列情報(単語の語順)を無視していることにほかなりません。そこでAttentionという手法が提案され、単語の語順を考慮するようになりました。
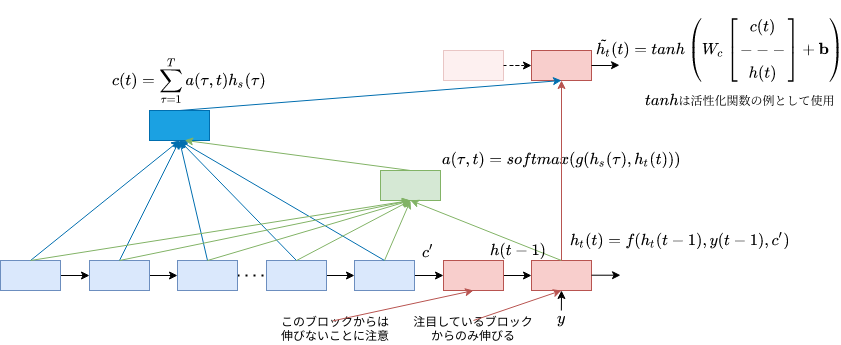
またEncoder-Decoderモデルは、再帰計算が必要なLSTMやGRUを使って長期記憶を実現しているため、並列計算ができず学習速度が遅いという欠点があります。そこで[3]では、Positional Encodingを利用することで、時系列データに直接順序・位置関係の情報を埋め込み、再帰計算を無くしています。
Attentionは、元々翻訳元(ソース)と翻訳先(ターゲット)を組み合わせて計算を行っていました[1][2]。これをSource-Target Attentionと言います(Source-Target Attentionと言い出したのは、[3]からのようですが)。これに加え、TransformerではSource-Source、Target-Targetの組み合わせのAttentionも使われていて、Self-Attentionと総称されています。Self Attentionは、Source-Target AttentionがTargetの隠れ層にSourceの時系列情報の考慮を目的としていることを踏まえると、自身の時系列情報を考慮して隠れ層を学習していくことが目的と考えられます。TransformerではLSTMなどの長期記憶を用いていないので、そういう観点でもSelf Attentionを利用する意図が理解できます。
Positional Encodingは、テキストから生成されたID行列に対し、各単語の位置情報(Aという単語はi番目で、Bという単語は・・・、のような情報)を組み込むことを目的に導入されました。[5]が解説としてわかりやすいかと思います。Positional Encodingは、各単語に対して下記のpを追加します。下記の式のtは単語の位置、kはk < Position Encoding出力の次元数/2、を満たす正数を表します。
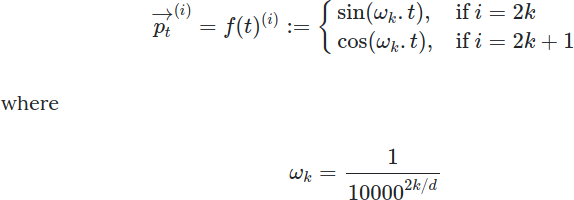
最終的に求まるpは、
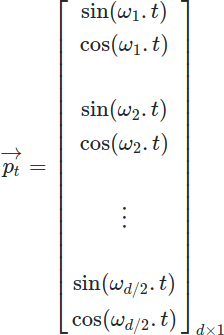
となります。[5]では、これは位置をビットで表現するようなもので、浮動小数点でビット表現するのはイマイチなのでsin/cosを使っているとと言っています。

参考文献
1. "NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE"
2. "Effective approaches to attention-based neural machine translation"
3. "Attention is all you need"
4. 巣籠悠輔, "詳細ディープラーニング 第二版", 2019
5. Amirhossein Kazemnejad, "Transformer Architecture: The Positional Encoding", 2019
6. Ilya Sutskever, et al., "Sequence to Sequence Learning with Neural Networks", arXiv, 2014.